KD-Crowd: a knowledge distillation framework for learning from crowds
Shaoyuan LI(), Yuxiang ZHENG, Ye SHI, Shengjun HUANG, Songcan CHEN
College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, MIIT Key Laboratory of Pattern Analysis and Machine Intelligence, Nanjing 211106, China
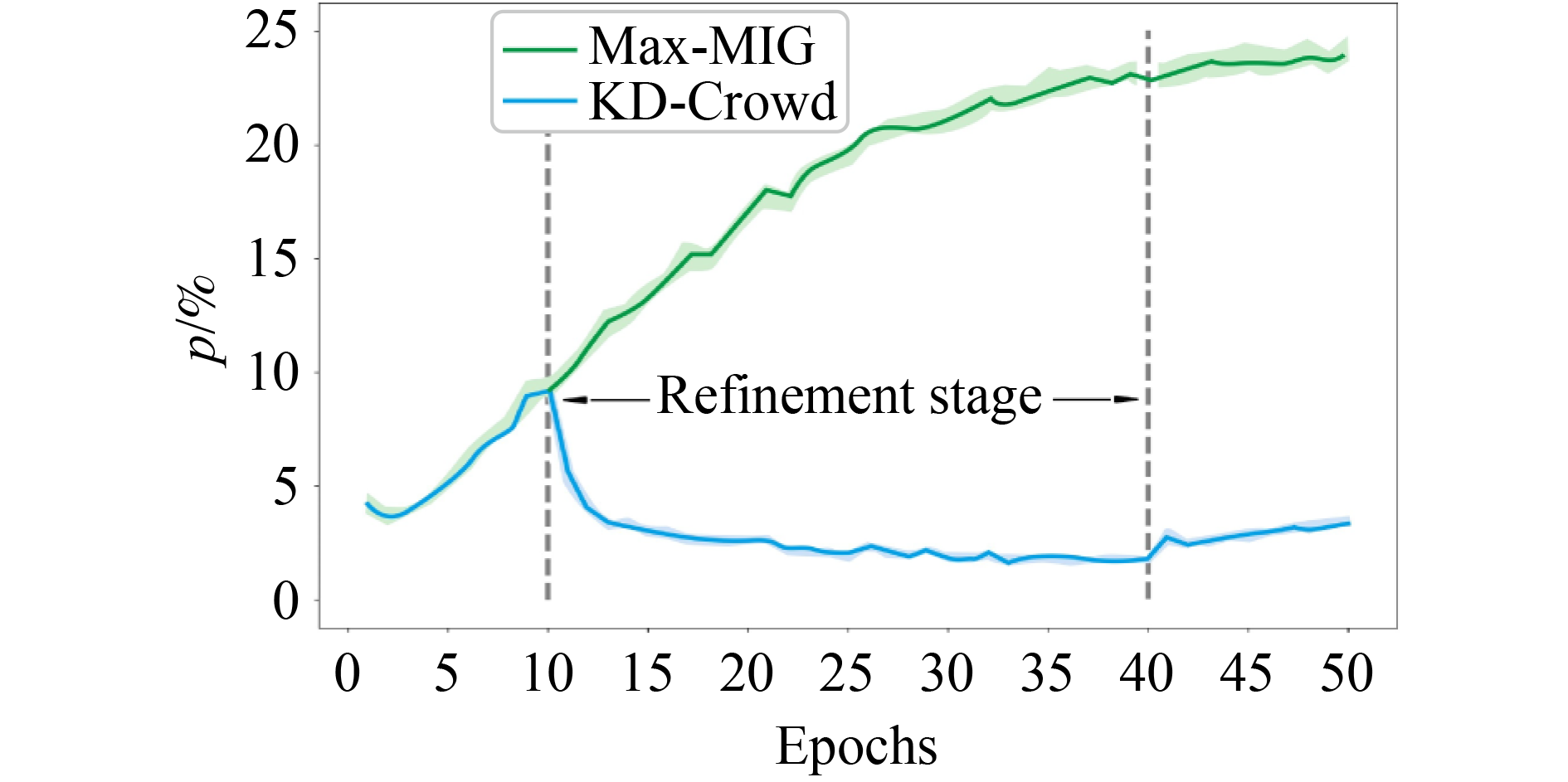
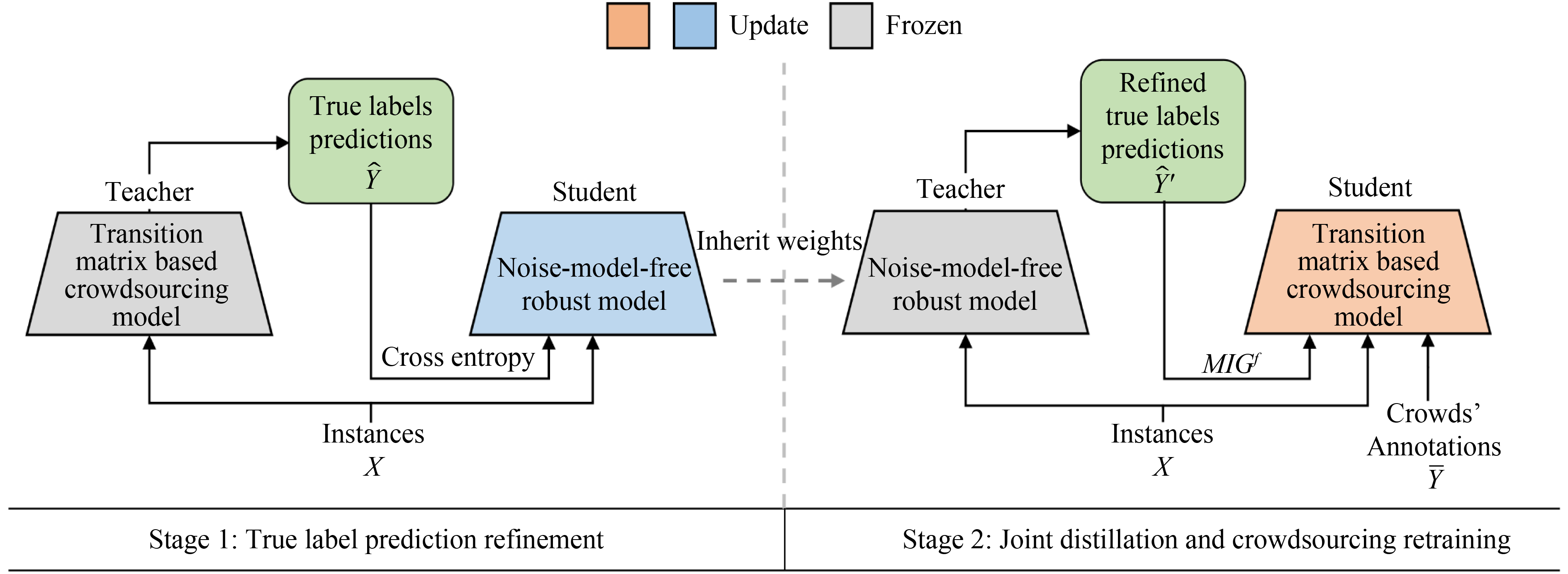
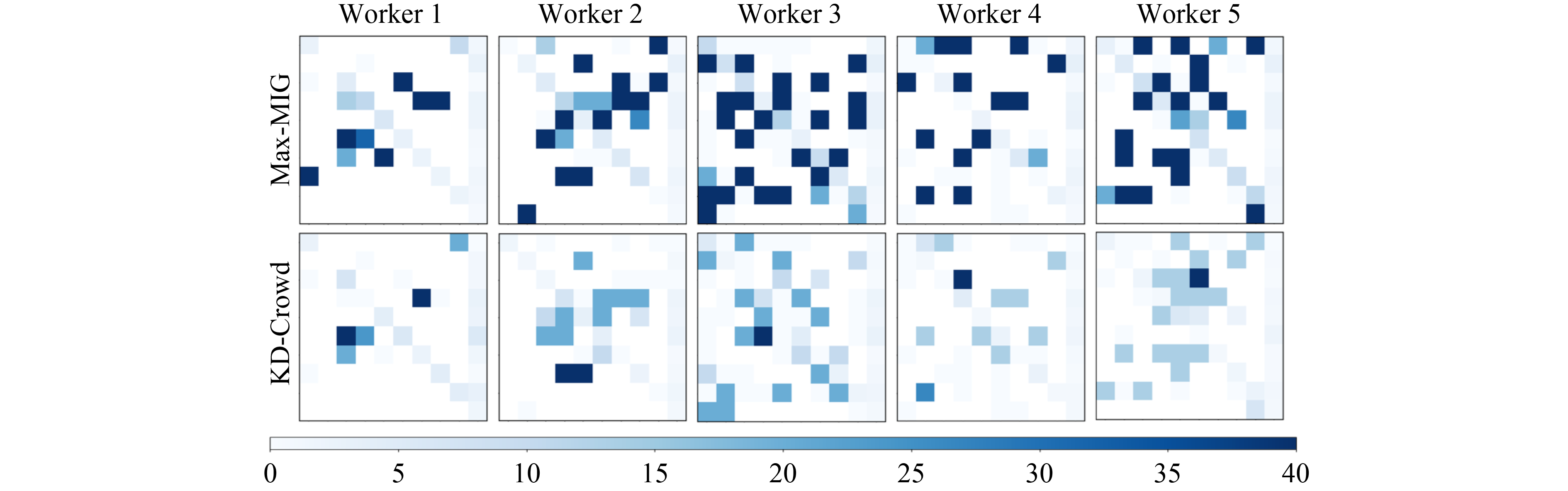
Recently, crowdsourcing has established itself as an efficient labeling solution by distributing tasks to crowd workers. As the workers can make mistakes with diverse expertise, one core learning task is to estimate each worker’s expertise, and aggregate over them to infer the latent true labels. In this paper, we show that as one of the major research directions, the noise transition matrix based worker expertise modeling methods commonly overfit the annotation noise, either due to the oversimplified noise assumption or inaccurate estimation. To solve this problem, we propose a knowledge distillation framework (KD-Crowd) by combining the complementary strength of noise-model-free robust learning techniques and transition matrix based worker expertise modeling. The framework consists of two stages: in Stage 1, a noise-model-free robust student model is trained by treating the prediction of a transition matrix based crowdsourcing teacher model as noisy labels, aiming at correcting the teacher’s mistakes and obtaining better true label predictions; in Stage 2, we switch their roles, retraining a better crowdsourcing model using the crowds’ annotations supervised by the refined true label predictions given by Stage 1. Additionally, we propose one f-mutual information gain () based knowledge distillation loss, which finds the maximum information intersection between the student’s and teacher’s prediction. We show in experiments that achieves obvious improvements compared to the regular KL divergence knowledge distillation loss, which tends to force the student to memorize all information of the teacher’s prediction, including its errors. We conduct extensive experiments showing that, as a universal framework, KD-Crowd substantially improves previous crowdsourcing methods on true label prediction and worker expertise estimation.
R, Snow B, O’Connor D, Jurafsky A Y Ng . Cheap and fast - but is it good?: evaluating non-expert annotations for natural language tasks. In: Proceedings of Conference on Empirical Methods in Natural Language Processing. 2008, 254−263
2
V C, Raykar S, Yu L H, Zhao G H, Valadez C, Florin L, Bogoni L Moy . Learning from crowds. The Journal of Machine Learning Research, 2010, 11: 1297–1322
3
S, Albarqouni C, Baur F, Achilles V, Belagiannis S, Demirci N Navab . AggNet: deep learning from crowds for mitosis detection in breast cancer histology images. IEEE Transactions on Medical Imaging, 2016, 35( 5): 1313–1321
4
Rodrigues F, Pereira F. Deep learning from crowds. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence, 30th Innovative Applications of Artificial Intelligence Conference, and 8th AAAI Symposium on Educational Advances in Artificial Intelligence. 2017, 197
5
Yang Y, Wei H, Zhu H, Yu D, Xiong H, Yang J. Exploiting crossmodal prediction and relation consistency for semisupervised image captioning. IEEE Transactions on Cybernetics, 2022, doi: 10.1109/TCYB.2022.3156367
6
A P, Dawid A M Skene . Maximum likelihood estimation of observer error-rates using the EM algorithm. Applied Statistics, 1979, 28( 1): 20–28
7
P, Cao Y, Xu Y, Kong Y Wang . Max-MIG: an information theoretic approach for joint learning from crowds. In: Proceedings of the 7th International Conference on Learning Representations. 2019
8
N, Natarajan I S, Dhillon P, Ravikumar A Tewari . Learning with noisy labels. In: Proceedings of the 27th Annual Conference on Neural Information Processing Systems. 2013, 1196−1204
9
D, Arpit S, Jastrzebski N, Ballas D, Krueger E, Bengio M S, Kanwal T, Maharaj A, Fischer A, Courville Y, Bengio S Lacoste-Julien . A closer look at memorization in deep networks. In: Proceedings of the 34th International Conference on Machine Learning. 2017, 233−242
10
X-J, Gui W, Wang Z-H Tian . Towards understanding deep learning from noisy labels with small-loss criterion. In: Proceedings of the 30th International Joint Conference on Artificial Intelligence. 2021, 2469−2475
11
L, Jiang Z, Zhou T, Leung L-J, Li F-F Li . MentorNet: learning data-driven curriculum for very deep neural networks on corrupted labels. In: Proceedings of the 35th International Conference on Machine Learning. 2018, 2304−2313
12
B, Han Q, Yao X, Yu G, Niu M, Xu W, Hu I W, Tsang M Sugiyama . Co-teaching: robust training of deep neural networks with extremely noisy labels. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. 2018, 8536−8546
13
X, Yu B, Han J, Yao G, Niu I, Tsang M Sugiyama . How does disagreement help generalization against label corruption? In: Proceedings of the 36th International Conference on Machine Learning. 2019, 7164−7173
14
E, Malach S Shalev-Shwartz . Decoupling “when to update” from “how to update”. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017, 961−971
15
J, Li R, Socher S C H Hoi . DivideMix: learning with noisy labels as semi-supervised learning. In: Proceedings of the 8th International Conference on Learning Representations. 2020
16
S, Liu J, Niles-Weed N, Razavian C Fernandez-Granda . Early-learning regularization prevents memorization of noisy labels. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. 2020, 1707
17
H, Song M, Kim J G Lee . SELFIE: refurbishing unclean samples for robust deep learning. In: Proceedings of the 36th International Conference on Machine Learning. 2019, 5907−5915
18
Q, Liu J, Peng A T Ihler . Variational inference for crowdsourcing. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. 2012, 692−700
19
D, Zhou J C, Platt S, Basu Y Mao . Learning from the wisdom of crowds by minimax entropy. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. 2012, 2195−2203
20
F, Rodrigues F C, Pereira B Ribeiro . Gaussian process classification and active learning with multiple annotators. In: Proceedings of the 31st International Conference on Machine Learning. 2014, 433−441
21
Guan M Y, Gulshan V, Dai A M, Hinton G E. Who said what: modeling individual labelers improves classification. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence and 30th Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence. 2018
22
R, Tanno A, Saeedi S, Sankaranarayanan D C, Alexander N Silberman . Learning from noisy labels by regularized estimation of annotator confusion. In: Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019, 11236−11245
23
Chu Z, Ma J, Wang H. Learning from crowds by modeling common confusions. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence AAAI 2021, 33rd Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, and 11th Symposium on Educational Advances in Artificial Intelligence. 2021, 5832−5840
24
S-Y, Li S-J, Huang S Chen . Crowdsourcing aggregation with deep Bayesian learning. Science China Information Sciences, 2021, 64( 3): 130104
25
Y, Shi S-Y, Li S-J Huang . Learning from crowds with sparse and imbalanced annotations. Machine Learning, 2023, 112( 6): 1823–1845
26
S-Y, Li Y, Jiang N V, Chawla Z-H Zhou . Multi-label learning from crowds. IEEE Transactions on Knowledge and Data Engineering, 2019, 31( 7): 1369–1382
27
K, Lee S, Yun K, Lee H, Lee B, Li J Shin . Robust inference via generative classifiers for handling noisy labels. In: Proceedings of the 36th International Conference on Machine Learning. 2019, 3763−3772
28
Y, Yao T, Liu B, Han M, Gong J, Deng G, Niu M Sugiyama . Dual T: reducing estimation error for transition matrix in label-noise learning. In: Proceedings of the 34th Conference on Neural Information Processing Systems. 2020, 7260−7271
29
Ghosh A, Kumar H, Sastry P S. Robust loss functions under label noise for deep neural networks. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. 2017, 1919−1925
30
Z, Zhang M R Sabuncu . Generalized cross entropy loss for training deep neural networks with noisy labels. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. 2018, 8792−8802
31
X, Ma H, Huang Y, Wang S R S, Erfani J Bailey . Normalized loss functions for deep learning with noisy labels. In: Proceedings of the 37th International Conference on Machine Learning. 2020, 607
32
Li M, Soltanolkotabi M, Oymak S. Gradient descent with early stopping is provably robust to label noise for overparameterized neural networks. In: Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics. 2020, 4313−4324
33
G, Hinton O, Vinyals J Dean . Distilling the knowledge in a neural network. 2015. arXiv preprint arXiv: 1503.02531
34
Z-H, Zhou Y, Jiang S-F Chen . Extracting symbolic rules from trained neural network ensembles. AI Communications, 2003, 16( 1): 3–15
35
Z-H, Zhou Y Jiang . NeC4.5: neural ensemble based C4.5. IEEE Transactions on Knowledge and Data Engineering, 2004, 16( 6): 770–773
36
N, Li Y, Yu Z-H Zhou . Diversity regularized ensemble pruning. In: Proceedings of Joint European Conference on Machine Learning and Knowledge Discovery in Databases. 2012, 330−345
37
Y, Li J, Yang Y, Song L, Cao J, Luo L-J Li . Learning from noisy labels with distillation. In: Proceedings of IEEE International Conference on Computer Vision. 2017, 1928−1936
38
Z, Zhang H, Zhang S Ö, Arik H, Lee T Pfister . Distilling effective supervision from severe label noise. In: Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020, 9291−9300
39
Yang Y, Zhan D-C, Fan Y, Jiang Y, Zhou Z-H. Deep learning for fixed model reuse. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. 2017, 2831−2837
40
Q, Xie M T, Luong E, Hovy Q V Le . Self-training with noisy student improves ImageNet classification. In: Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020, 10684−10695
41
E D, Cubuk B, Zoph J, Shlens Q V Le . Randaugment: practical automated data augmentation with a reduced search space. In: Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020, 3008−3017
42
A Krizhevsky . Learning multiple layers of features from tiny images. University of Toronto, Dissertation, 2009
43
X, Xia T, Liu B, Han N, Wang M, Gong H, Liu G, Niu D, Tao M Sugiyama . Part-dependent label noise: towards instance-dependent label noise. In: Proceedings of the 34th Conference on Neural Information Processing Systems. 2020, 7597−7610
44
J C, Peterson R M, Battleday T L, Griffiths O Russakovsky . Human uncertainty makes classification more robust. In: Proceedings of IEEE/CVF International Conference on Computer Vision. 2019, 9617−9626
45
K, He X, Zhang S, Ren J Sun . Deep residual learning for image recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. 2016, 770−778
46
N, Ma X, Zhang H-T, Zheng J Sun . ShuffleNet V2: practical guidelines for efficient CNN architecture design. In: Proceedings of the 15th European Conference on Computer Vision. 2018, 122−138