|
|
|
Empirically revisiting and enhancing automatic classification of bug and non-bug issues |
Zhong LI1,2, Minxue PAN1,3( ), Yu PEI4, Tian ZHANG1,2, Linzhang WANG1,2, Xuandong LI1,2 ), Yu PEI4, Tian ZHANG1,2, Linzhang WANG1,2, Xuandong LI1,2 |
1. State Key Laboratory for Novel Software Technology, Nanjing University, Nanjing 210023, China
2. Department of Computer Science and Technology, Nanjing University, Nanjing 210023, China
3. Software Institute, Nanjing University, Nanjing 210093, China
4. Department of Computing, The Hong Kong Polytechnic University, Hong Kong, China |
|
|
|
|
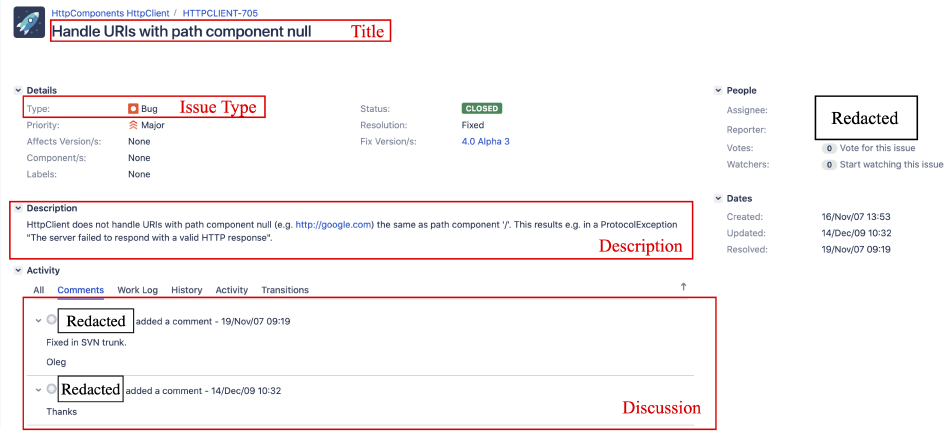
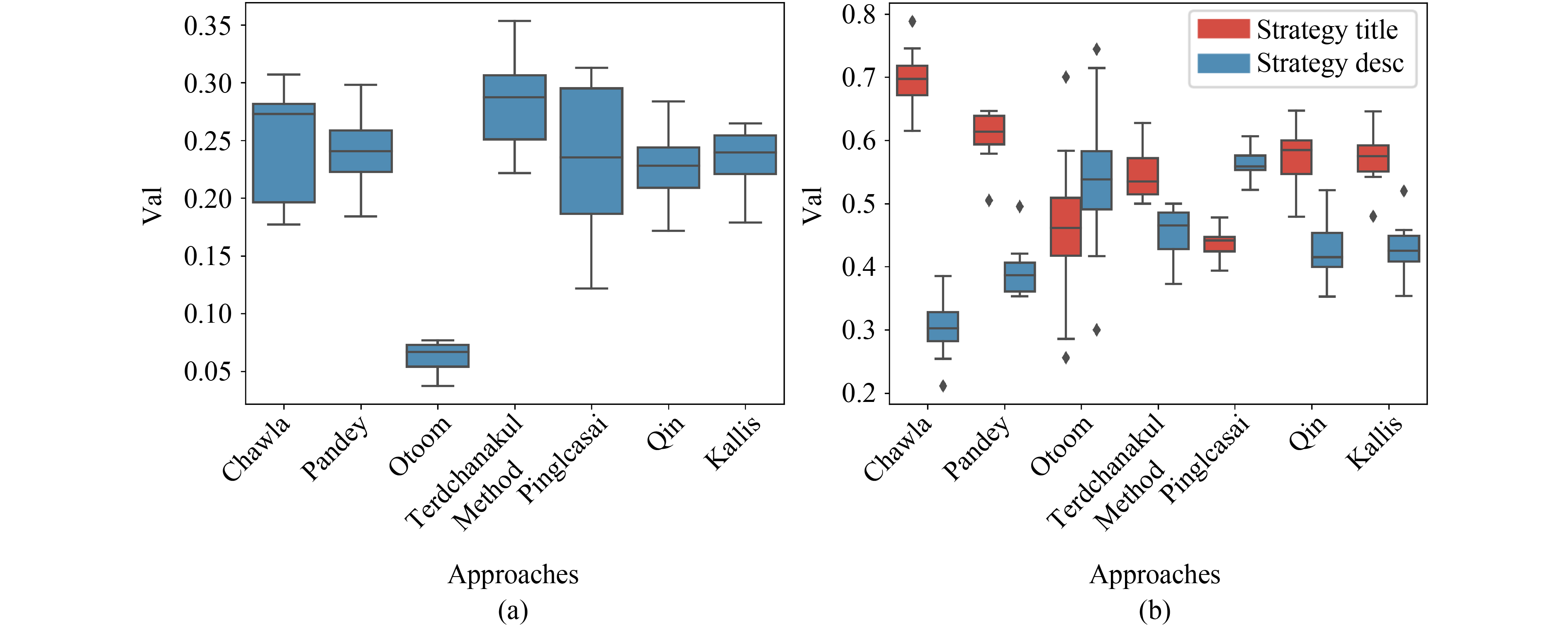
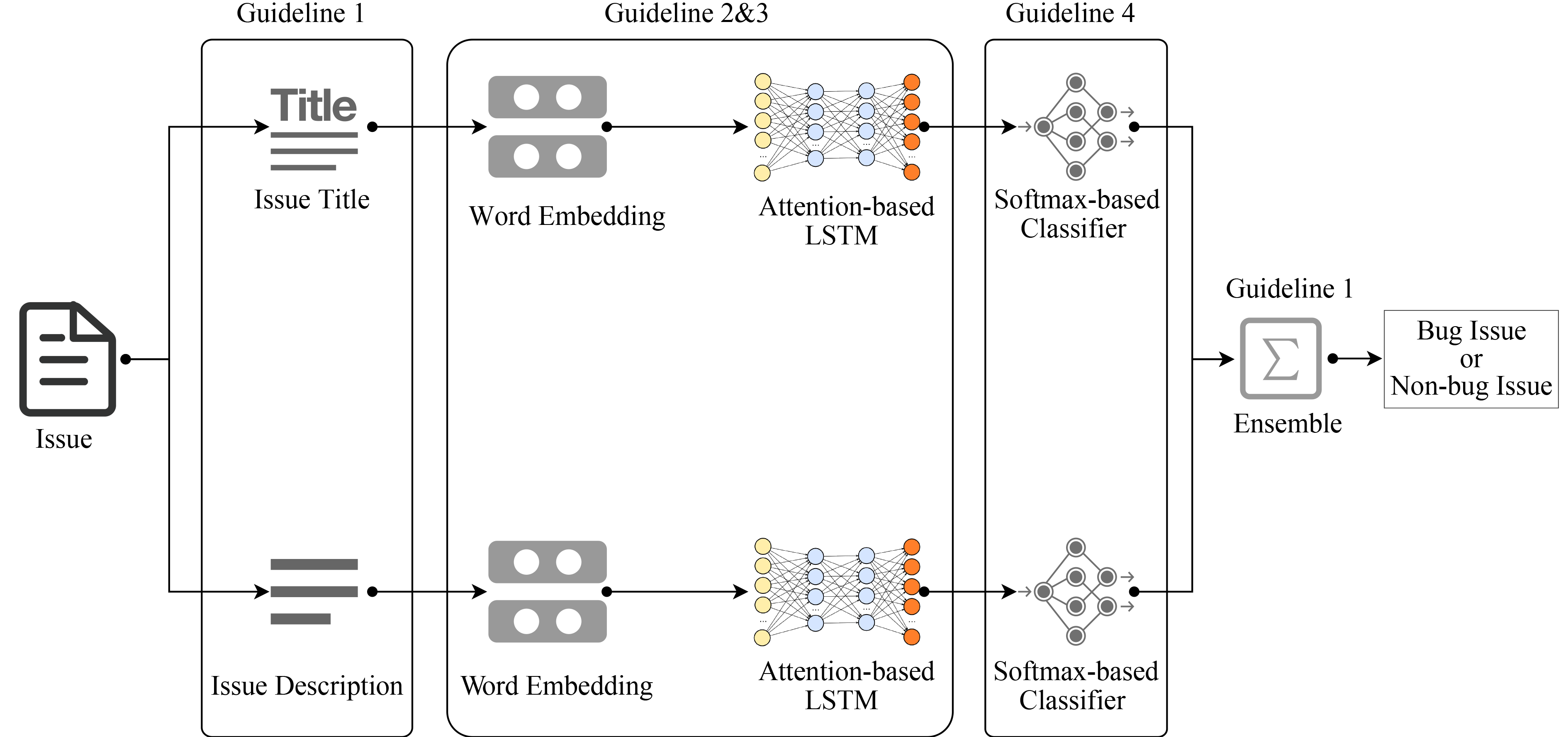
Abstract A large body of research effort has been dedicated to automated issue classification for Issue Tracking Systems (ITSs). Although the existing approaches have shown promising performance, the different design choices, including the different textual fields, feature representation methods and machine learning algorithms adopted by existing approaches, have not been comprehensively compared and analyzed. To fill this gap, we perform the first extensive study of automated issue classification on 9 state-of-the-art issue classification approaches. Our experimental results on the widely studied dataset reveal multiple practical guidelines for automated issue classification, including: (1) Training separate models for the issue titles and descriptions and then combining these two models tend to achieve better performance for issue classification; (2) Word embedding with Long Short-Term Memory (LSTM) can better extract features from the textual fields in the issues, and hence, lead to better issue classification models; (3) There exist certain terms in the textual fields that are helpful for building more discriminating classifiers between bug and non-bug issues; (4) The performance of the issue classification model is not sensitive to the choices of ML algorithms. Based on our study outcomes, we further propose an advanced issue classification approach, DEEPLABEL, which can achieve better performance compared with the existing issue classification approaches.
|
| Keywords
issue tracking
issue type prediction
empirical study
|
|
Corresponding Author(s):
Minxue PAN
|
|
Just Accepted Date: 05 June 2023
Issue Date: 10 July 2023
|
|
| 1 |
T, Merten B, Mager P, Hübner T, Quirchmayr B, Paech S Bürsner . Requirements communication in issue tracking systems in four open-source projects. In: Proceedings of the Joint Proceedings of REFSQ-2015 Workshops, Research Method Track, and Poster Track Co-Located with the 21st International Conference on Requirements Engineering: Foundation for Software Quality. 2015, 114−125
|
| 2 |
D, Bertram A, Voida S, Greenberg R Walker . Communication, collaboration, and bugs: the social nature of issue tracking in small, collocated teams. In: Proceedings of 2010 ACM Conference on Computer Supported Cooperative Work. 2010, 291−300
|
| 3 |
T F, Bissyandé D, Lo L, Jiang L, Réveillère J, Klein Traon Y Le . Got issues? Who cares about it? A large scale investigation of issue trackers from GitHuB. In: Proceedings of the 24th International Symposium on Software Reliability Engineering. 2013, 188−197
|
| 4 |
Y, Yan D, Cheng J E, Feng H, Li J Yue . Survey on applications of algebraic state space theory of logical systems to finite state machines. Science China Information Sciences, 2023, 66( 1): 111201
|
| 5 |
Q, Fan Y, Yu G, Yin T, Wang H Wang . Where is the road for issue reports classification based on text mining?. In: Proceedings of 2017 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. 2017, 121−130
|
| 6 |
S, Breu R, Premraj J, Sillito T Zimmermann . Information needs in bug reports: improving cooperation between developers and users. In: Proceedings of 2010 ACM Conference on Computer Supported Cooperative Work. 2010, 301−310
|
| 7 |
N, Limsettho H, Hata A, Monden K Matsumoto . Automatic unsupervised bug report categorization. In: Proceedings of the 6th International Workshop on Empirical Software Engineering in Practice. 2014, 7−12
|
| 8 |
M, Hammad R, Alzyoudi A F Otoom . Automatic clustering of bug reports. International Journal of Advanced Computer Research, 2018, 8( 39): 313–323
|
| 9 |
I, Chawla S K Singh . Automated labeling of issue reports using semi supervised approach. Journal of Computational Methods in Sciences and Engineering, 2018, 18( 1): 177–191
|
| 10 |
G, Antoniol K, Ayari Penta M, Di F, Khomh Y G Guéhéneuc . Is it a bug or an enhancement?: a text-based approach to classify change requests. In: Proceedings of the 28th Annual International Conference on Computer Science and Software Engineering. 2018, 2−16
|
| 11 |
N, Pingclasai H, Hata K I Matsumoto . Classifying bug reports to bugs and other requests using topic modeling. In: Proceedings of the 20th Asia-Pacific Software Engineering Conference. 2013, 13−18
|
| 12 |
N, Limsettho H, Hata K I Matsumoto . Comparing hierarchical dirichlet process with latent dirichlet allocation in bug report multiclass classification. In: Proceedings of the 15th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing. 2014, 1−6
|
| 13 |
I, Chawla S K Singh . An automated approach for bug categorization using fuzzy logic. In: Proceedings of the 8th India Software Engineering Conference. 2015, 90−99
|
| 14 |
Y, Zhou Y, Tong R, Gu H Gall . Combining text mining and data mining for bug report classification. Journal of Software: Evolution and Process, 2016, 28( 3): 150–176
|
| 15 |
P, Terdchanakul H, Hata P, Phannachitta K Matsumoto . Bug or not? Bug report classification using N-Gram IDF. In: Proceedings of 2017 IEEE International Conference on Software Maintenance and Evolution. 2017, 534−538
|
| 16 |
N, Pandey D K, Sanyal A, Hudait A Sen . Automated classification of software issue reports using machine learning techniques: an empirical study. Innovations in Systems and Software Engineering, 2017, 13( 4): 279–297
|
| 17 |
H, Qin X Sun . Classifying bug reports into bugs and non-bugs using LSTM. In: Proceedings of the 10th Asia-Pacific Symposium on Internetware. 2018, 20
|
| 18 |
M S, Zolkeply J Shao . Classifying software issue reports through association mining. In: Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing. 2019, 1860−1863
|
| 19 |
A F, Otoom S, Al-Jdaeh M Hammad . Automated classification of software bug reports. In: Proceedings of the 9th International Conference on Information Communication and Management. 2019, 17−21
|
| 20 |
R, Kallis Sorbo A, Di G, Canfora S Panichella . Ticket tagger: machine learning driven issue classification. In: Proceedings of 2019 IEEE International Conference on Software Maintenance and Evolution. 2019, 406−409
|
| 21 |
K, Herzig S, Just A Zeller . It’s not a bug, it’s a feature: how misclassification impacts bug prediction. In: Proceedings of the 35th International Conference on Software Engineering. 2013, 392−401
|
| 22 |
Z, Li M, Pan Y, Pei T, Zhang L, Wang X Li . DeepLabel: automated issue classification for issue tracking systems. In: Proceedings of the 13th Asia-Pacific Symposium on Internetware. 2022, 231−241
|
| 23 |
M, Ortu G, Destefanis M, Kassab M Marchesi . Measuring and understanding the effectiveness of JIRA developers communities. In: Proceedings of the 6th IEEE/ACM International Workshop on Emerging Trends in Software Metrics. 2015, 3−10
|
| 24 |
C Wohlin . Guidelines for snowballing in systematic literature studies and a replication in software engineering. In: Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering. 2014, 38
|
| 25 |
N, Limsettho H, Hata A, Monden K Matsumoto . Unsupervised bug report categorization using clustering and labeling algorithm. International Journal of Software Engineering and Knowledge Engineering, 2016, 26( 7): 1027–1053
|
| 26 |
N, Pandey A, Hudait D K, Sanyal A Sen . Automated classification of issue reports from a software issue tracker. In: Sa P K, Sahoo M N, Murugappan M, Wu Y, Majhi B, eds. Progress in Intelligent Computing Techniques: Theory, Practice, and Applications. Singapore: Springer, 2018, 423−430
|
| 27 |
S, Hochreiter J Schmidhuber . Long short-term memory. Neural Computation, 1997, 9( 8): 1735–1780
|
| 28 |
A, Joulin E, Grave P, Bojanowski T Mikolov . Bag of tricks for efficient text classification. In: Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. 2017, 427−431
|
| 29 |
S, Herbold A, Trautsch F Trautsch . On the feasibility of automated prediction of bug and non-bug issues. In: Koziolek A, Schaefer I, Seidl C, eds. Software Engineering 2021. Bonn: Gesellschaft für Informatik e.V., 2021, 55−56
|
| 30 |
Q, Perez P A, Jean C, Urtado S Vauttier . Bug or not bug? That is the question. In: Proceedings of the 29th IEEE/ACM International Conference on Program Comprehension. 2021, 47−58
|
| 31 |
A, Trautsch F, Trautsch S, Herbold B, Ledel J Grabowski . The SmartSHARK ecosystem for software repository mining. In: Proceedings of the 42nd International Conference on Software Engineering. 2020, 25−28
|
| 32 |
J, Han M, Kamber J Pei . Data Mining: Concepts and Techniques. 3rd ed. San Francisco: Morgan Kaufmann, 2011
|
| 33 |
P S, Kochhar F, Thung D Lo . Automatic fine-grained issue report reclassification. In: Proceedings of the 19th International Conference on Engineering of Complex Computer Systems. 2014, 126−135
|
| 34 |
Z, Li Y, Yu G, Yin T, Wang Q, Fan H Wang . Automatic classification of review comments in pull-based development model. In: Proceedings of the 29th International Conference on Software Engineering and Knowledge Engineering. 2017, 572−577
|
| 35 |
J W Tukey . Comparing individual means in the analysis of variance. Biometrics, 1949, 5( 2): 99–114
|
| 36 |
A, Vaswani N, Shazeer N, Parmar J, Uszkoreit L, Jones A N, Gomez L, Kaiser I Polosukhin . Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017, 6000−6010
|
| 37 |
T, Mikolov K, Chen G, Corrado J Dean . Efficient estimation of word representations in vector space. In: Proceedings of the 1st International Conference on Learning Representations. 2013
|
| 38 |
D, Bahdanau K, Cho Y Bengio . Neural machine translation by jointly learning to align and translate. In: Proceedings of the 3rd International Conference on Learning Representations. 2015
|
| 39 |
F Wilcoxon . Individual comparisons by ranking methods. In: Kotz S, Johnson N L, eds. Breakthroughs in Statistics: Methodology and Distribution. New York: Springer, 1992, 196−202
|
| 40 |
N Cliff . Ordinal Methods for Behavioral Data Analysis. New York: Psychology Press, 1996
|
| 41 |
Y, Fan X, Xia Costa D A, da D, Lo A E, Hassan S Li . The impact of mislabeled changes by SZZ on just-in-time defect prediction. IEEE Transactions on Software Engineering, 2021, 47( 8): 1559–1586
|
| 42 |
T, Wolf L, Debut V, Sanh J, Chaumond C, Delangue A, Moi P, Cistac T, Rault R, Louf M, Funtowicz J, Davison S, Shleifer Platen P, von C, Ma Y, Jernite J, Plu C, Xu Scao T, Le S, Gugger M, Drame Q, Lhoest A Rush . Transformers: state-of-the-art natural language processing. In: Proceedings of 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020, 38−45
|
| 43 |
S, Wiegreffe Y Pinter . Attention is not not explanation. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 2019, 11−20
|
| 44 |
C H, Chang E, Creager A, Goldenberg D Duvenaud . Explaining image classifiers by counterfactual generation. In: Proceedings of the 7th International Conference on Learning Representations. 2019
|
| 45 |
P, Dabkowski Y Gal . Real time image saliency for black box classifiers. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017, 6970−6979
|
| 46 |
R, Fong M, Patrick A Vedaldi . Understanding deep networks via extremal perturbations and smooth masks. In: Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. 2019, 2950−2958
|
| 47 |
R C, Fong A Vedaldi . Interpretable explanations of black boxes by meaningful perturbation. In: Proceedings of the IEEE International Conference on Computer Vision. 2017, 3449−3457
|
| 48 |
R R, Selvaraju M, Cogswell A, Das R, Vedantam D, Parikh D Batra . Grad-CAM: visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision. 2017, 618−626
|
| 49 |
A, Shrikumar P, Greenside A Kundaje . Learning important features through propagating activation differences. In: Proceedings of the 34th International Conference on Machine Learning. 2017, 3145−3153
|
| 50 |
J T, Springenberg A, Dosovitskiy T, Brox M A Riedmiller . Striving for simplicity: the all convolutional net. In: Proceedings of the 3rd International Conference on Learning Representations. 2015
|
| 51 |
M T, Ribeiro S, Singh C Guestrin . "Why should I trust you?": explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016, 1135−1144
|
| 52 |
S M, Lundberg S I Lee . A unified approach to interpreting model predictions. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017, 4768−4777
|
| 53 |
W, Guo D, Mu J, Xu P, Su G, Wang X Xing . LEMNA: explaining deep learning based security applications. In: Proceedings of 2018 ACM SIGSAC Conference on Computer and Communications Security. 2018, 364−379
|
| 54 |
M, Gegick P, Rotella T Xie . Identifying security bug reports via text mining: an industrial case study. In: Proceedings of the 7th International Working Conference on Mining Software Repositories. 2010, 11−20
|
| 55 |
H B, McMahan G, Holt D, Sculley M, Young D, Ebner J, Grady L, Nie T, Phillips E, Davydov D, Golovin S, Chikkerur D, Liu M, Wattenberg A M, Hrafnkelsson T, Boulos J Kubica . Ad click prediction: a view from the trenches. In: Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2013, 1222−1230
|
| 56 |
D, Sahoo Q, Pham J, Lu S C H Hoi . Online deep learning: learning deep neural networks on the fly. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. 2018, 2660−2666
|
| 57 |
S C H, Hoi D, Sahoo J, Lu P Zhao . Online learning: a comprehensive survey. Neurocomputing, 2021, 459: 249–289
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|