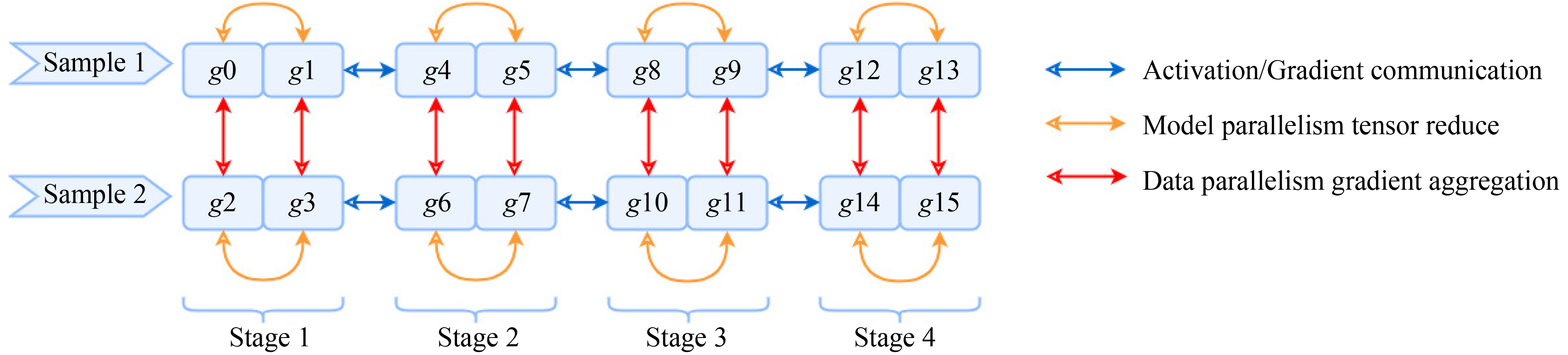
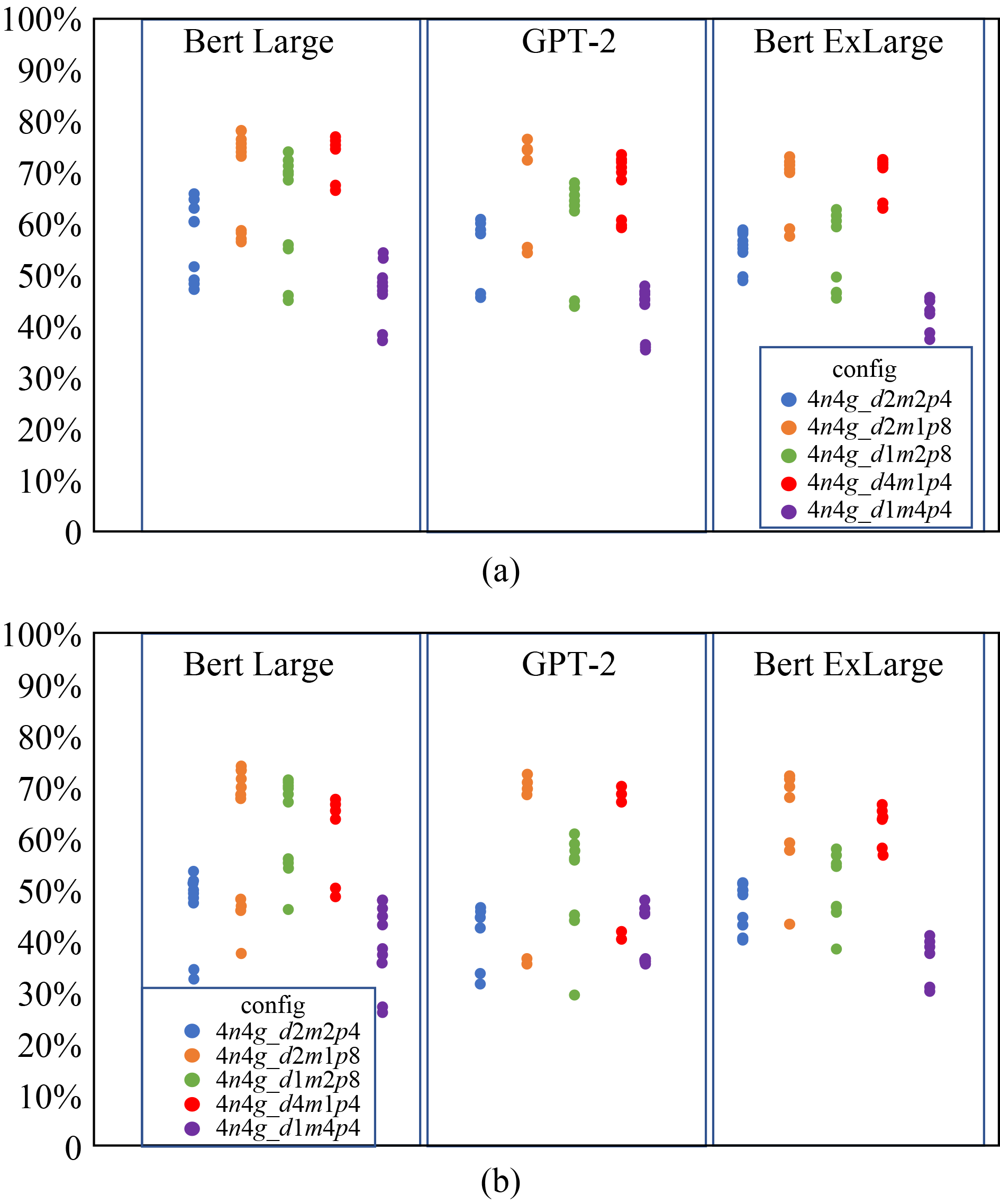
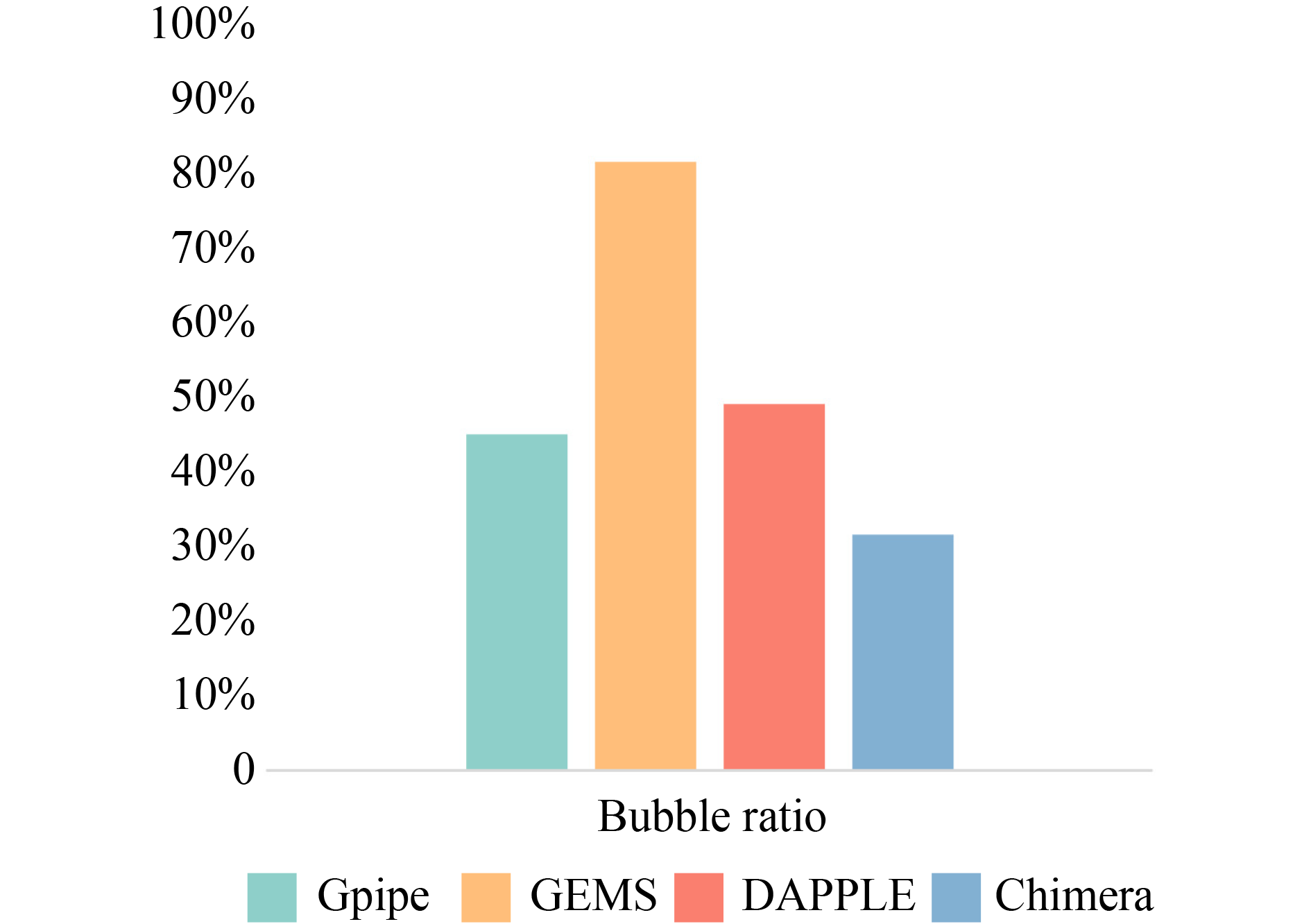
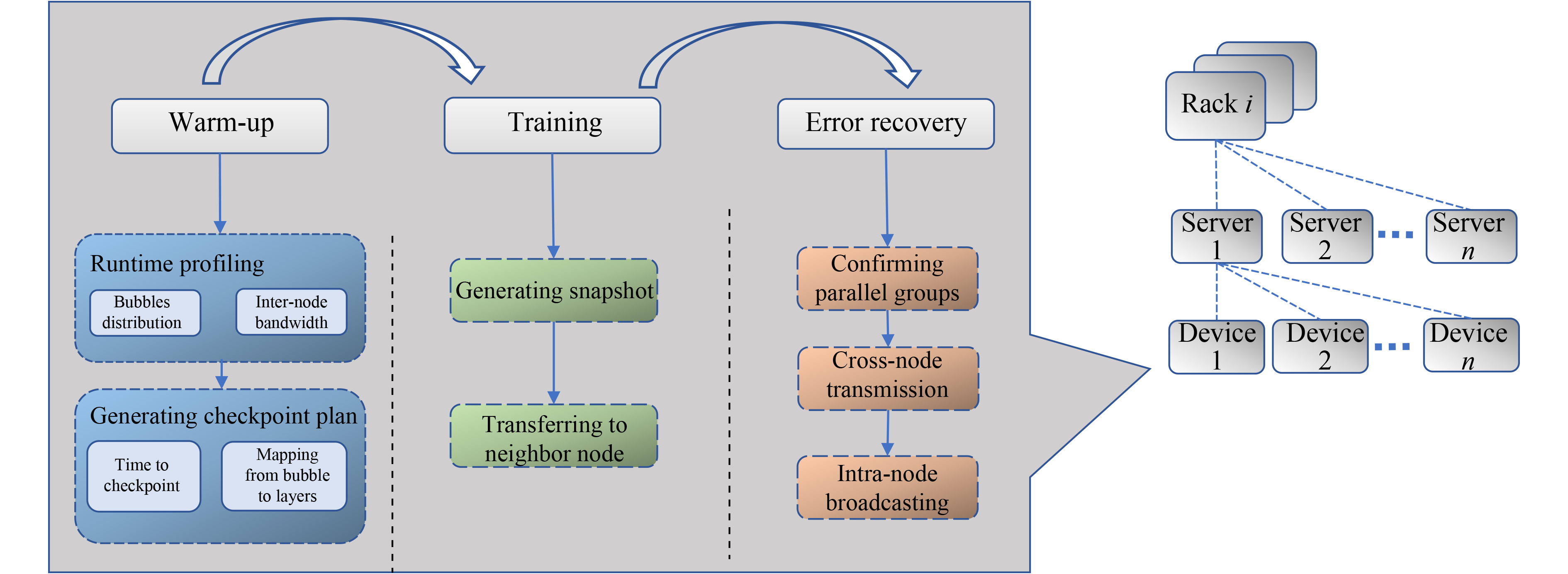
|
|
|
BAFT: bubble-aware fault-tolerant framework for distributed DNN training with hybrid parallelism |
Runzhe CHEN1,2, Guandong LU1,2, Yakai WANG1,2, Rui ZHANG3, Zheng HU3, Yanming MIAO3, Zhifang CAI3, Jingwen LENG1,2( ), Minyi GUO1,2() ), Minyi GUO1,2() |
1. School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
2. Shanghai Qi Zhi Institution, Shanghai 200232, China
3. Huawei Technologies Co., Ltd, Shenzhen 518129, China |
|
|
|
|
Abstract As deep neural networks (DNNs) have been successfully adopted in various domains, the training of these large-scale models becomes increasingly difficult and is often deployed on compute clusters composed of many devices like GPUs. However, as the size of the cluster increases, so does the possibility of failures during training. Currently, faults are mainly handled by recording checkpoints and recovering, but this approach causes large overhead and affects the training efficiency even when no error occurs. The low checkpointing frequency leads to a large loss of training time, while the high recording frequency affects the training efficiency. To solve this contradiction, we propose BAFT, a bubble-aware fault tolerant framework for hybrid parallel distributed training. BAFT can automatically analyze parallel strategies, profile the runtime information, and schedule checkpointing tasks at the granularity of pipeline stage depending on the bubble distribution in the training. It supports higher checkpoint efficiency and only introduces less than 1% time overhead, which allows us to record checkpoints at high frequency, thereby reducing the time loss in error recovery and avoiding the impact of fault tolerance on training.
|
| Keywords
distributed training
fault tolerance
checkpoint
pipeline parallelism
error recovery
|
|
Corresponding Author(s):
Jingwen LENG,Minyi GUO
|
|
Just Accepted Date: 13 September 2023
Issue Date: 18 March 2024
|
|
| 1 |
A, Krizhevsky I, Sutskever G E Hinton . ImageNet classification with deep convolutional neural networks. Communications of the ACM, 2017, 60( 6): 84–90
|
| 2 |
T B, Brown B, Mann N, Ryder M, Subbiah J, Kaplan P, Dhariwal A, Neelakantan P, Shyam G, Sastry A, Askell S, Agarwal A, Herbert-Voss G, Krueger T, Henighan R, Child A, Ramesh D M, Ziegler J, Wu C, Winter C, Hesse M, Chen E, Sigler M, Litwin S, Gray B, Chess J, Clark C, Berner S, McCandlish A, Radford I, Sutskever D Amodei . Language models are few-shot learners. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. 2020, 159
|
| 3 |
C, Guo C, Zhang J, Leng Z, Liu F, Yang Y, Liu M, Guo Y Zhu . Ant: exploiting adaptive numerical data type for low-bit deep neural network quantization. In: Proceedings of the 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). 2022, 1414−1433
|
| 4 |
Y, Wang C, Zhang Z, Xie C, Guo Y, Liu J Leng . Dual-side sparse tensor core. In: Proceedings of the 48th ACM/IEEE Annual International Symposium on Computer Architecture (ISCA). 2021, 1083−1095
|
| 5 |
C, Guo B Y, Hsueh J, Leng Y, Qiu Y, Guan Z, Wang X, Jia X, Li M, Guo Y A Zhu . Accelerating sparse DNN models without hardware-support via tile-wise sparsity. In: Procedings of SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. 2020, 1-15
|
| 6 |
C, Guo Y, Qiu J, Leng C, Zhang Y, Cao Q, Zhang Y, Liu F, Yang M Guo . Nesting forward automatic differentiation for memory-efficient deep neural network training. In: Proceeding of the 40th IEEE International Conference on Computer Design (ICCD). 2022, 738−745
|
| 7 |
J, Choquette W Gandhi . NVIDIA A100 GPU: performance & innovation for GPU computing. In: Proceedings of 2020 IEEE Hot Chips 32 Symposium (HCS). 2020, 1−43
|
| 8 |
Z, Liu J, Leng Z, Zhang Q, Chen C, Li Guo M and . VELTAIR: towards high-performance multi-tenant deep learning services via adaptive compilation and scheduling. In: Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '22). 2022, 388–401
|
| 9 |
M, Jeon S, Venkataraman A, Phanishayee U, Qian W, Xiao F Yang . Analysis of large-scale multi-tenant GPU clusters for DNN training workloads. In: Proceedings of 2019 USENIX Conference on USENIX Annual Technical Conference. 2019 , 947−960
|
| 10 |
D, Gizopoulos G, Papadimitriou A, Chatzidimitriou V J, Reddi B, Salami O S, Unsal A C, Kestelman J Leng . Modern hardware margins: Cpus, gpus, fpgas recent system-level studies. In: Proceedings of the 25th IEEE International Symposium on On-Line Testing and Robust System Design (IOLTS). 2019, 129–134
|
| 11 |
G, Papadimitriou A, Chatzidimitriou D, Gizopoulos V J, Reddi J, Leng B, Salami O S, Unsal A C Kestelman . Exceeding conservative limits: a consolidated analysis on modern hardware margins. IEEE Transactions on Device and Materials Reliability, 2020, 20(2): 341–350
|
| 12 |
Y, Qiu J, Leng C, Guo Q, Chen C, Li M, Guo Y Zhu . Adversarial defense through network profiling based path extraction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019, 4777–4786
|
| 13 |
J, Leng A, Buyuktosunoglu R, Bertran P, Bose Q, Chen M, Guo Reddi V Janapa . Asymmetric resilience: exploiting task-level idempotency for transient error recovery in accelerator-based systems. In: Proceedings of 2020 IEEE International Symposium on High Performance Com puter Architecture (HPCA). 2020, 44–57
|
| 14 |
J, Mohan A, Phanishayee V Chidambaram . CheckFreq: Frequent, fine-grained DNN checkpointing. In: Proceedings of the 19th USENIX Conference on File and Storage Technologies (FAST 21). 2021, 203−216
|
| 15 |
A, Eisenman K K, Matam S, Ingram D, Mudigere R, Krishnamoorthi K, Nair M, Smelyanskiy M Annavaram . Check-N-Run: a checkpointing system for training deep learning recommendation models. In: Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22). 2022, 929−943
|
| 16 |
B, Nicolae J, Li J M, Wozniak G, Bosilca M, Dorier F Cappello . DeepFreeze: towards scalable asynchronous checkpointing of deep learning models. In: Proceedings of the 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID). 2020, 172−181
|
| 17 |
S, Li Y, Zhao R, Varma O, Salpekar P, Noordhuis T, Li A, Paszke J, Smith B, Vaughan P, Damania S Chintala . PyTorch distributed: experiences on accelerating data parallel training. Proceedings of the VLDB Endowment, 2020, 13( 12): 3005–3018
|
| 18 |
W, Zeng X, Ren T, Su H, Wang Y, Liao Z, Wang X, Jiang Z, Yang K, Wang X, Zhang C, Li Z, Gong Y, Yao X, Huang J, Wang J, Yu Q, Guo Y, Yu Y, Zhang J, Wang H, Tao D, Yan Z, Yi F, Peng F, Jiang H, Zhang L, Deng Y, Zhang Z, Lin C, Zhang S, Zhang M, Guo S, Gu G, Fan Y, Wang X, Jin Q, Liu Y Tian . PanGu-α: large-scale autoregressive pretrained Chinese language models with auto-parallel computation. 2021, arXiv preprint arXiv: 2104.12369
|
| 19 |
D, Narayanan M, Shoeybi J, Casper P, LeGresley M, Patwary V, Korthikanti D, Vainbrand P, Kashinkunti J, Bernauer B, Catanzaro A, Phanishayee M Zaharia . Efficient large-scale language model training on GPU clusters using megatron-LM. In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 2021, 58
|
| 20 |
L, Zheng Z, Li H, Zhang Y, Zhuang Z, Chen Y, Huang Y, Wang Y, Xu D, Zhuo E P, Xing J, Gonzalez I Stoica . Alpa: automating inter- and intra-operator parallelism for distributed deep learning. In: Proceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation. 2022, 559−578
|
| 21 |
Y, Xu H, Lee D, Chen B A, Hechtman Y, Huang R, Joshi M, Krikun D, Lepikhin A, Ly M, Maggioni R, Pang N, Shazeer S, Wang T, Wang Y, Wu Z Chen . GSPMD: general and scalable parallelization for ML computation graphs. 2021, arXiv preprint arXiv: 2105.04663
|
| 22 |
S, Li T Hoefler . Chimera: efficiently training large-scale neural networks with bidirectional pipelines. In: Proceedings of SC21: International Conference for High Performance Computing, Networking, Storage and Analysis. 2021, 1−14
|
| 23 |
A, Radford K Narasimhan . Improving language understanding by generative pre-training. 2018
|
| 24 |
A, Vaswani N, Shazeer N, Parmar J, Uszkoreit L, Jones A N, Gomez Ł, Kaiser I Polosukhin . Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017, 6000−6010
|
| 25 |
S, Merity C, Xiong J, Bradbury R Socher . Pointer sentinel mixture models. In: Proceedings of the 5th International Conference on Learning Representations. 2017
|
| 26 |
Y, Chen Q, Yang S, He Z, Shi J Chen . FTPipeHD: a fault-tolerant pipeline-parallel distributed training framework for heterogeneous edge devices. 2021, arXiv preprint arXiv: 2110.02781
|
| 27 |
B, Nicolae A, Moody E, Gonsiorowski K, Mohror F Cappello . VeloC: towards high performance adaptive asynchronous checkpointing at large scale. In: Proceedings of 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS). 2019, 911−920
|
| 28 |
P, Li E, Koyuncu H Seferoglu . Respipe: resilient model-distributed DNN training at edge networks. In: Proceedings of 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2021, 3660−3664
|
| 29 |
K, Maeng S, Bharuka I, Gao M C, Jeffrey V, Saraph B Y, Su C, Trippel J, Yang M, Rabbat B, Lucia C J Wu . CPR: understanding and improving failure tolerant training for deep learning recommendation with partial recovery. 2020, arXiv preprint arXiv: 2011.02999
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|